Does AI hallucinate? Yes…..but what if we could rate the hallucinations created by different LLMs to benchmark their performance.
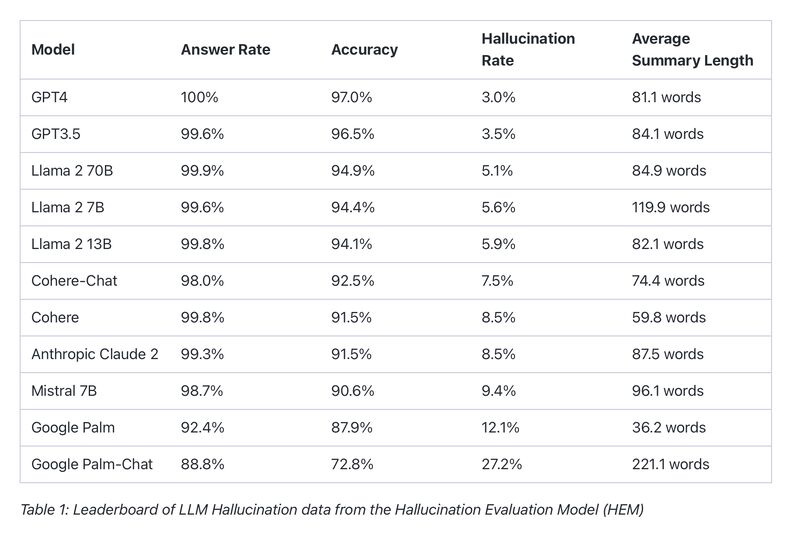
Vectara has released Hallucination Evaluation Model (HEM), an open source model to evaluate AI generation and measure AI accuracy.
Just like a personal credit score, it creates ratings for various LLMs that will be updated frequently.
Here are some highlights:
+ It is aimed at detecting and quantifying hallucinations in Retrieval Augmented Generation (RAG) systems.
+ Provides a FICO-like score for grading LLMs, crucial for businesses considering AI adoption.
+ The model addresses major concerns about AI-generated errors, like misinformation or biases.
+ HEM’s leaderboard offers an objective comparison of popular models like GPT-4, Cohere, and Google Palm.
+ Vectara’s model opens the door for safer AI integration in sectors where factual accuracy is non-negotiable.
From the current leaderboard, it seems that GPTs and Llama are faring better with lower hallucinations than Cohere or PaLM. But time will tell as LLMs evolve and these evaluations become more accurate.
What are your thoughts on LLM accuracy benchmarking and collaboration?
#generativeai #hallucinations #aibusiness #aichallenges #aicompliance
Data: Vector / Github
